


Gli algoritmi di intelligenza artificiali sono indubbiamente sulla cresta dell'onda, dato che negli ultimi mesi non si è fatto altro che parlare di chatbot e creatori di testi come ChatGPT o generatori di immagini come Dall-E 2. Generalmente, questi strumenti fanno affidamento su giganteschi datacenter dotati di apparecchiature di ultima generazione per svolgere tutti i calcoli necessari per le operazioni richieste, ma anche le moderne schede grafiche che equipaggiano i vostri PC contengono unità hardware dedicate a questo scopo. Ma quanto sono veloci effettivamente nello svolgere l'inferenza per IA?
Per scoprirlo abbiamo utilizzato Stable Diffusion, un popolare creatore di immagini tramite IA, mettendolo alla prova con le più recenti schede grafiche di NVIDIA, AMD e Intel. Per i nostri test abbiamo usato tre diverse versioni di Stable Diffusion, poiché nessuno dei pacchetti funzionava perfettamente su tutte le GPU. Per NVIDIA, abbiamo scelto la versione webui di Automatic 1111, mentre per le GPU AMD abbiamo utilizzato la versione Shark di Nod.ai e, infine, per quelle Arc di Intel abbiamo optato per Stable Diffusion OpenVINO.
I risultati dei test sulla serie NVIDIA 30 sono stati soddisfacenti, in particolare quando si abilita xformers, che fornisce un ulteriore incremento delle prestazioni del 20%. Tuttavia, quelli sulla serie RTX 40 sono stati un po' inferiori alle aspettative, probabilmente a causa della mancanza di ottimizzazioni per la nuova architettura Ada Lovelace. Anche i risultati su AMD sono contrastanti, con le GPU RDNA 3 che si sono comportate abbastanza bene, mentre quelle RDNA 2 hanno arrancato un po'. Infine, le GPU Intel hanno avuto prestazioni finali simili a quelle AMD, nonostante i tempi di rendering significativamente più lunghi, probabilmente a causa dei processi in background. È stata impiegata la versione 1.4 di Stable Diffusion, al posto delle più recenti edizioni 2.0 o 2.1, dato che far funzionare SD 2.1 su hardware non NVIDIA avrebbe richiesto una maggiore quantità di lavoro.
I parametri per i test sono stati gli stessi per tutte le GPU:
Positive Prompt:postapocalyptic steampunk city, exploration, cinematic, realistic, hyper detailed, photorealistic maximum detail, volumetric light, (((focus))), wide-angle, (((brightly lit))), (((vegetation))), lightning, vines, destruction, devastation, wartorn, ruinsNegative Prompt:(((blurry))), ((foggy)), (((dark))), ((monochrome)), sun, (((depth of field)))
Steps:100
Classifier Free Guidance:15.0
Sampling Algorithm:Some Euler variant (Ancestral, Discrete)
L'algoritmo di campionamento non sembra influire in modo significativo sulle prestazioni, anche se può influenzare l'output. Automatic 1111 offre il maggior numero di opzioni, mentre la build Intel OpenVINO non offre alcuna scelta. Nella tabella sottostante potete vedere i risultati ottenuti: è possibile notare che ogni GPU NVIDIA presenta due risultati, uno che utilizza il modello di calcolo predefinito (in nero) e un secondo che utilizza la più efficiente libreria "xformers" di Facebook (in verde).
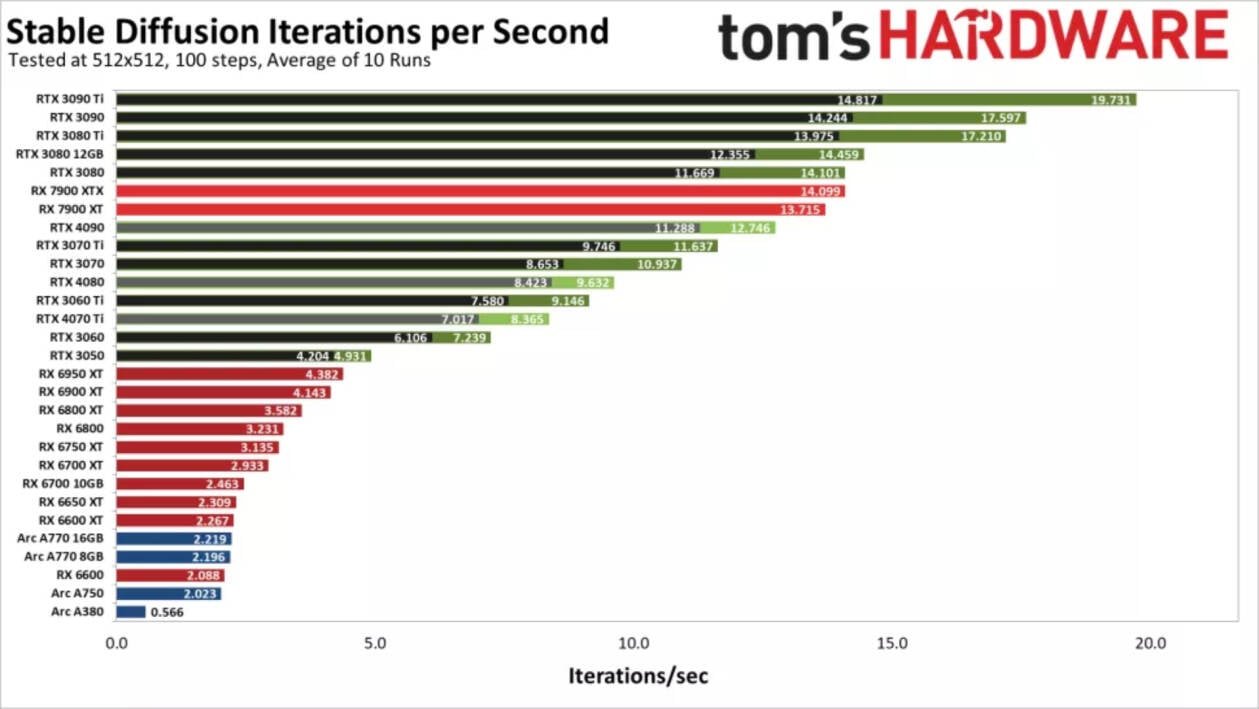
Come previsto, le GPU di NVIDIA offrono prestazioni superiori rispetto a quelle di AMD o Intel, sebbene siano presenti alcune anomalie. La GPU più veloce nei nostri test iniziali è stata la RTX 3090 Ti, che ha raggiunto quasi 20 iterazioni al secondo, o circa cinque secondi per immagine, utilizzando i parametri precedenti. A seguire, troviamo la RTX 3080 Ti che ha pareggiato con la nuova RX 7900 XTX di AMD, mentre la RTX 3050 Ti ha superato la RX 6950 XT.
Passiamo ora ai risultati che lasciano più interdetti. In primo luogo, ci aspettavamo che la RTX 4090 schiacciasse la concorrenza, ma chiaramente non è stato così. Infatti, è stata più lenta della 7900 XT e anche della RTX 3080. Allo stesso modo, la RTX 4080 si è collocata tra la 3070 e la 3060 Ti, mentre la RTX 4070 Ti si è piazzata tra la 3060 e la 3060 Ti. Molto probabilmente, applicando delle ottimizzazioni adeguate si potrebbero facilmente raddoppiare le prestazioni della serie RTX 40.
Le GPU Arc di Intel offrono attualmente risultati molto deludenti, soprattutto perché supportano operazioni XMX (matriciali) che dovrebbero garantire un throughput fino a quattro volte superiore rispetto ai normali calcoli FP32. Sospettiamo che anche l'attuale progetto Stable Diffusion OpenVINO abbia un ampio margine di miglioramento. Questo si capisce già dal fatto che se per eseguire Stable Diffusione su una GPU Arc è necessario modificare il file 'stable_diffusion_engine.py' e cambiare "CPU" in "GPU", altrimenti non verrà utilizzerà la scheda grafica per i calcoli.
Riassumendo, possiamo dire che le schede NVIDIA della serie RTX 30 vanno benissimo, così come quelle AMD della serie RX 7000, mentre le RTX 40 offrono prestazioni inferiori, a cui seguono le RX 6000 e, infine, le GPU Arc. Le cose potrebbero cambiare radicalmente con un software aggiornato e, data la popolarità dell'intelligenza artificiale, ci aspettiamo che sia solo una questione di tempo prima di vedere sensibili miglioramenti. Nel grafico sottostante possiamo vedere le prestazioni teoriche FP16 (in TFLOPS) delle varie GPU, utilizzando i Tensor/Matrix core dove possibile.
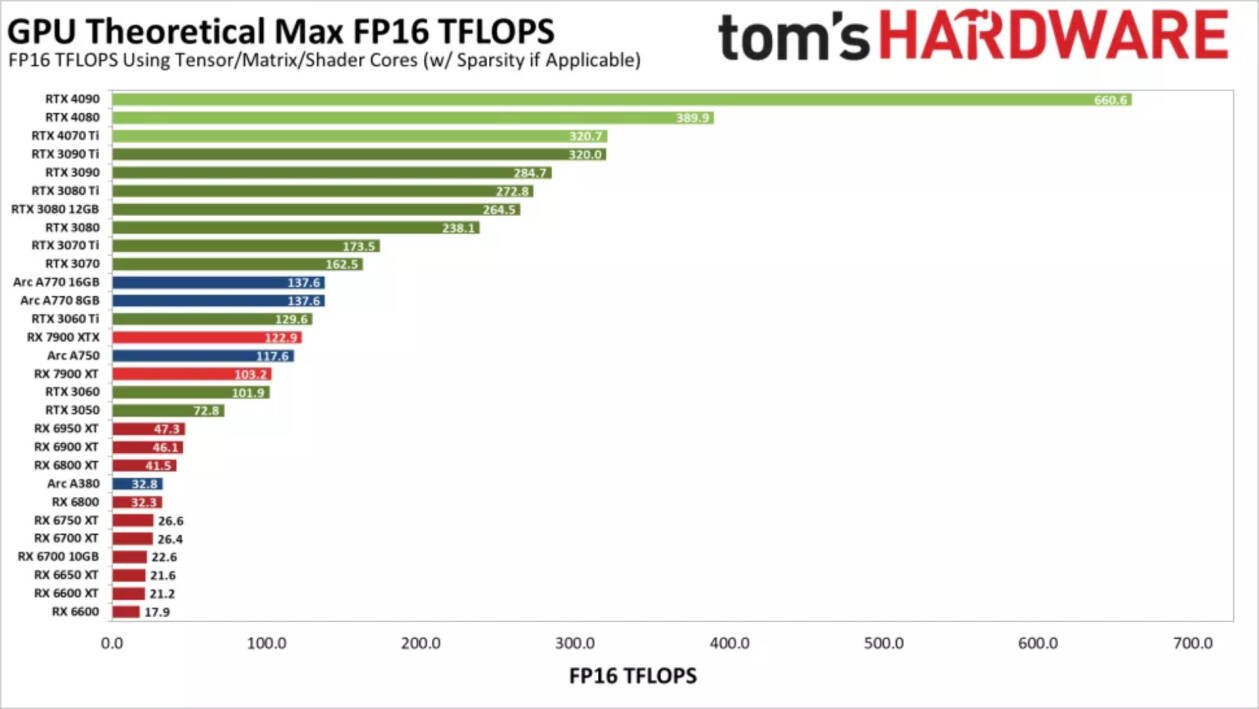
I Tensor Core delle schede grafiche NVIDIA sono chiaramente molto potenti, anche se i nostri test di Stable Diffusion hanno evidenziato prestazioni inferiori alle aspettative sulla serie RTX 40. Ad esempio, la RTX 4090 risulta più lenta del 35% rispetto alla RTX 3090 Ti, probabilmente a causa del software utilizzato (Automatic 1111) che non sfrutta al meglio le nuove istruzioni FP8 delle GPU Ada Lovelace, le quali potrebbero potenzialmente raddoppiare le performance.
Le GPU Arc invece non raggiungono nemmeno le prestazioni previste. I loro Matrix core dovrebbero fornire performance simili a quelli della RTX 3060 Ti e della RX 7900 XTX, con l'A380 vicina alla RX 6800, ma, nella pratica, non si avvicinano neanche lontanamente a questi valori. Infatti, le A770 si collocano tra la RX 6600 e la RX 6600 XT, la A750 è appena dietro la RX 6600 e la A380 offre circa un quarto della velocità della A750. Probabilmente, le schede grafiche utilizzano gli shader in modalità FP32 a piena precisione, diminuendo le loro performance a causa della mancanza di ottimizzazione.
Inoltre, possiamo notare che il calcolo teorico sulla RX 7900 XTX/XT è migliorato molto rispetto alla serie RX 6000 e la larghezza di banda della memoria non è un fattore critico: i modelli 3080 da 10GB e 12GB sono relativamente vicini. La RX 7900 XTX ha prestazioni quasi identiche a quelle della XTX, mentre teoricamente dovrebbe essere circa il 19% più veloce, rispetto al 3% riscontrato.
In definitiva, questi testi ci hanno consentito di scattare un'istantanea delle prestazioni di Stable Diffusion su GPU AMD, Intel e NVIDIA. Con varie ottimizzazioni, il grafico finale dovrebbe avvicinarsi più a quello dei TFLOP teorici e sicuramente le nuove RTX serie 40 non dovrebbero essere affatto inferiori alle precedenti RTX serie 30.
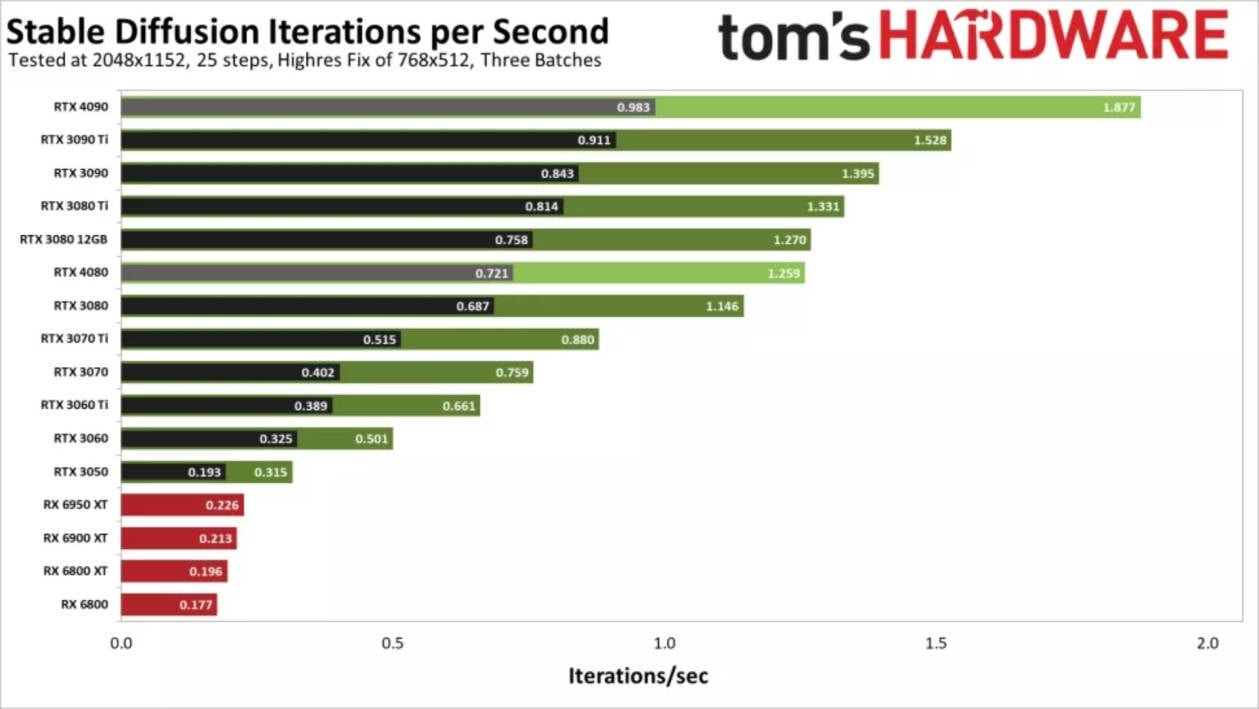
Infine, abbiamo effettuato alcuni test ad alta risoluzione, sebbene non siano state messe alla prova tutte le GPU precedenti e sia stato impiegato Linux sulle AMD RX serie 6000. Apparentemente, la risoluzione target di 2048x1152 è stata in grado di sfruttare maggiormente almeno la RTX 4090. Sarà interessante vedere come evolverà la situazione il prossimo anno.