


L’arrivo di Llama 4, la nuova generazione di modelli AI open source rilasciata da Meta, apre scenari concreti per l’adozione di intelligenza artificiale avanzata all’interno di aziende, studi professionali e organizzazioni pubbliche. Grazie a un’architettura multimodale e scalabile, i nuovi modelli promettono prestazioni elevate in attività di scrittura, analisi, supporto decisionale e automazione.
Può Llama 4 rappresentare un’alternativa concreta a soluzioni come ChatGPT, Microsoft Copilot o Claude di Anthropic, e in generale agli strumenti AI già diffusi e utilizati?

Il rilascio di Meta segna un punto di svolta, perché mette a disposizione della comunità – con licenze in parte aperte – modelli AI comparabili per capacità a quelli dei big player. Almeno in scenari limitati, tuttavia, sono strumenti che possono funzionare anche localmente o su server proprietari, andando a risolvere una delle criticità maggiori in tema di governance dei dati e riservatezza.

Per molte realtà, questo significa poter sviluppare assistenti virtuali su misura, analizzatori di dati interni, copiloti per l’ufficio o il customer care, senza dover dipendere da API proprietarie e licenze a consumo. Al tempo stesso, però, non mancano le incognite: prestazioni reali, requisiti hardware, rischi di sicurezza, sostenibilità economica e chiarezza normativa.
L’azienda di Mark Zuckerberg ha presentato Llama 4 come parte della famiglia di modelli Llama, sottolineandone fin da subito le capacità all’avanguardia e la natura aperta. Secondo Meta, Llama 4 rappresenta “l’inizio di una nuova era” per il suo ecosistema AI , forte di prestazioni da primato in compiti che vanno dalla programmazione alla comprensione di immagini.
Tuttavia, l’annuncio non è stato privo di controversie. Già nel weekend del lancio, alcuni osservatori hanno messo in dubbio la trasparenza dei test condotti: un dirigente di Meta è dovuto intervenire per smentire pubblicamente le voci secondo cui la società avrebbe addestrato i modelli Llama 4 su insiemi di test, gonfiando artificiosamente i punteggi nei benchmark di valutazione.
Non mancano comunque riscontri indipendenti che sembrano smentire almeno in parte le prestazioni strabilianti annunciate da Meta.
Che cos’è Llama 4: architettura, modelli e funzionalità
Llama 4 non è un singolo modello, ma un gruppo di modelli sviluppati da Meta, progettati per diversi scopi e dimensioni. In totale sono quattro le nuove varianti annunciate: Llama 4 Scout, Llama 4 Maverick, Llama 4 Behemoth e un modello orientato al “Reasoning” (ragionamento). I primi due – Scout e Maverick – sono già disponibili pubblicamente, mentre Behemoth e la versione Reasoning dovrebbero arrivare in un secondo momento.
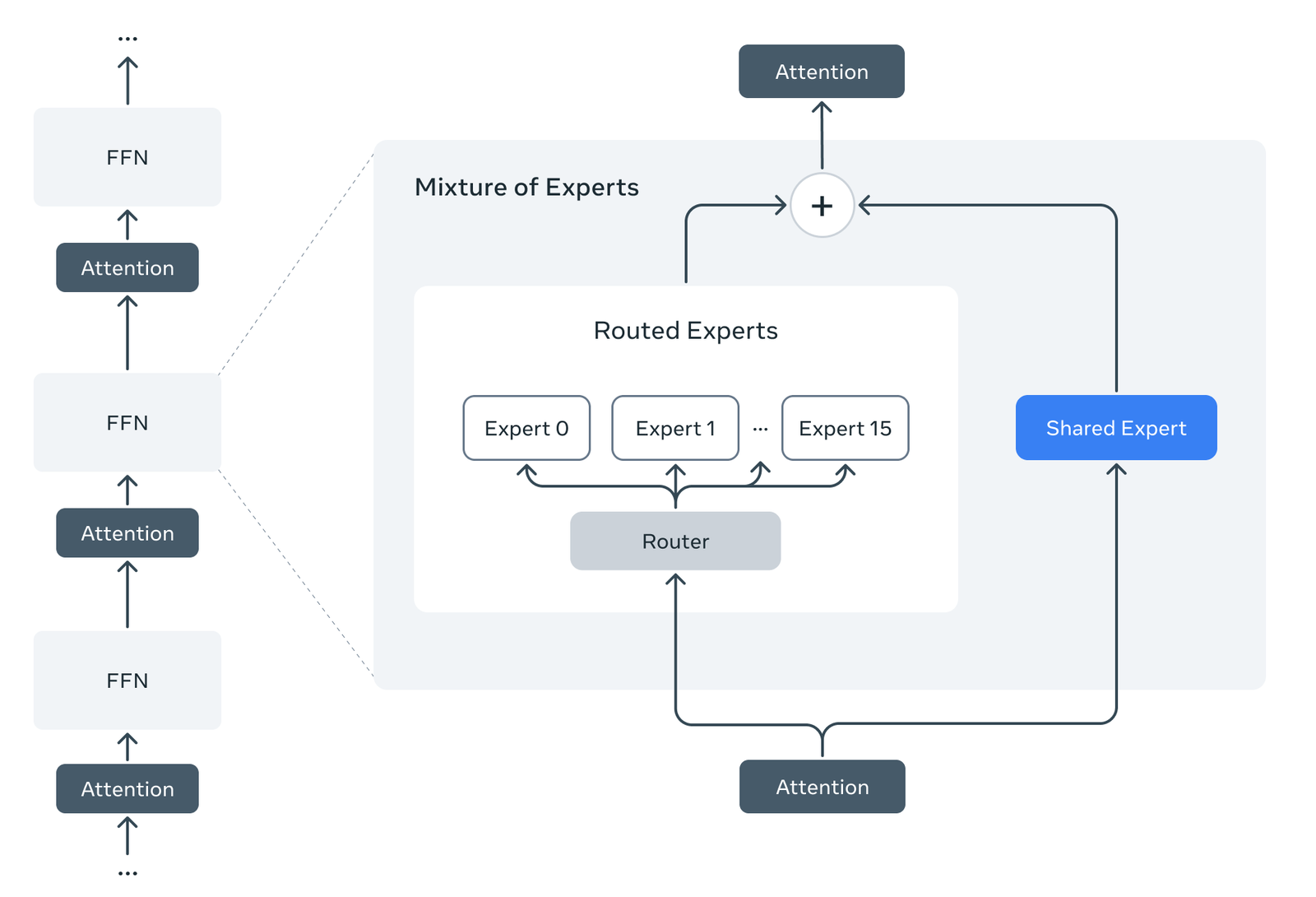
Tutti i modelli Llama 4 condividono un’innovativa architettura Mixture of Experts (MoE), che suddivide i compiti tra una serie di sottoreti specializzate (“esperti”) coordinate da un router centrale. Questo design consente al modello di attivare solo una piccola frazione dei parametri totali per ciascuna richiesta, risultando più efficiente sia nel training che nell’inferenza.
Ad esempio, Llama 4 Maverick possiede 400 miliardi di parametri totali ma ne impiega solo 17 miliardi per ogni input (distribuiti su 128 esperti). Allo stesso modo il più piccolo Llama 4 Scout utilizza 17 miliardi di parametri attivi su 16 esperti, a fronte di 109 miliardi di parametri complessivi. In pratica, grazie all’MoE ogni modello può contare su un enorme patrimonio di conoscenze (parametri totali) mantenendo al contempo tempi di risposta rapidi, poiché elabora le query attivando solo gli “esperti” necessari al caso.
Llama 4 Scout è il modello più compatto della famiglia ed è pensato per funzionare con risorse hardware relativamente limitate. Meta dichiara che Scout può girare su una singola GPU Nvidia H100 , il che lo rende accessibile per implementazioni on-premises o su cloud a costi contenuti.
Attenzione però, perché qui “costi contenuti” è relativo: una Nvidia H100 non costa meno di 25.000 dollari, e ne può costare anche 40mila. Vien da sé quindi che impegnare una cifra del genere per far funzionare una sola istanza AI è comunque molto impegnativo. Un approccio ben diverso rispetto a quello, per esempio, di Vitruvian - sistema meno potente ma che permette di eseguire numerose istanze su un solo sistema.
Fino a 10 milioni di token
Nonostante le dimensioni ridotte, Scout vanta alcune caratteristiche da record: è in grado di gestire un contesto esteso fino a 10 milioni di token, un valore senza precedenti nell’industria. In termini pratici, ciò significa poter fornire in input al modello interi libri, codici sorgente voluminosi o ampie collezioni di documenti, affinché vengano riassunti o analizzati in un’unica esecuzione.
Inoltre Scout supporta nativamente la multimodalità, ossia può ricevere in input non solo testo ma anche immagini, integrandole nel contesto della conversazione. Va notato, però, che attualmente esistono dei limiti pratici: al lancio, i servizi cloud che offrono Scout hanno imposto soglie molto inferiori (dell’ordine di 100-300 mila token al massimo) per la lunghezza del contesto utilizzabile. Il supporto ai 10 milioni di token completi richiederà ulteriori ottimizzazioni hardware e software, restando per ora una capacità più teorica che utilizzabile su larga scala.

Llama 4 Maverick rappresenta la versione di medio livello, una sorta di “fratello maggiore” di Scout per casi d’uso generali di assistant e chat. Condivide con Scout la dimensione dei parametri attivi (17 miliardi), ma grazie ai suoi 128 esperti dispone di un bagaglio di 400 miliardi di parametri totali, conferendogli maggiore versatilità e conoscenze più approfondite. Maverick è anch’esso un modello multimodale ma nativamente accetta “solo” un milione di token.
Date le dimensioni, Maverick è più esigente in termini computazionali: Meta indica che per eseguirlo è necessario un sistema DGX con GPU H100 multiple o equivalenti. Di conseguenza, Maverick si presta a implementazioni in cloud o su infrastrutture aziendali robuste, più che su singole workstation. Meta descrive Maverick come il modello Llama 4 ottimizzato per la creatività e la conversazione, adatto a generare testi, assistere nella stesura di contenuti e dialogare in linguaggio naturale.
Llama 4 Behemoth è il gigante del gruppo: un modello non ancora rilasciato pubblicamente al momento dell’annuncio, perché ancora in fase di addestramento, ma di cui Meta ha rivelato alcune specifiche impressionanti. Behemoth adotta l’architettura MoE spingendola al limite: dispone di 288 miliardi di parametri attivi suddivisi su 16 esperti, per un totale prossimo ai 2 trilioni di parametri (2 mila miliardi).
È un modello di dimensioni senza precedenti per Meta, pensato come “modello insegnante” per il distillation degli altri membri della famiglia. In altre parole, Behemoth funge da rete di riferimento ultra-capace da cui derivare, tramite tecniche di distillazione, le versioni più piccole (come Scout e Maverick), trasferendo loro parte delle proprie abilità.
Secondo Meta, Behemoth è destinato a diventare uno dei modelli linguistici più intelligenti al mondo, con capacità avanzate specialmente in ambito tecnico-scientifico (ad esempio nella risoluzione di problemi matematici). È prevedibile che le risorse hardware necessarie per far funzionare Behemoth siano fuori dalla portata della maggior parte delle aziende - basti considerare che Meta stessa si è messa in casa quasi un milione di Nvidia H100.
Di fatto Behemoth potrebbe rimanere confinato ai data center di Meta o di pochi partner strategici.
Infine, Meta ha anticipato l’arrivo di un modello Llama 4 dedicato al “Reasoning”, cioè al ragionamento e alla verifica fattuale delle risposte fornite. Questo modello, atteso nelle prossime settimane dopo il lancio iniziale, sarebbe più vicino alla categoria dei cosiddetti retriever-augmented o “self-reflection” models che effettuano controlli incrociati sulle proprie affermazioni.
Nessuno dei modelli Llama 4 attualmente distribuiti, infatti, implementa di default un meccanismo avanzato di fact-checking interno: “nessuno dei Llama 4 è un vero modello di ‘ragionamento’ sullo stile di OpenAI”, osserva TechCrunch. I modelli di reasoning tendono a fornire risposte più affidabili perché consultano fonti o controllano le proprie affermazioni, al prezzo però di una maggiore latenza nelle risposte. Meta sembra quindi intenzionata a colmare questa lacuna con un modello dedicato, per competere meglio con soluzioni concorrenti.
Multimodalità nativa
Un altro aspetto chiave di Llama 4 è la multimodalità nativa. A differenza dei precedenti modelli Llama, addestrati principalmente su testo, i modelli della serie 4 sono stati pre-addestrati su grandi quantità di dati di testo, immagini e video, così da sviluppare una “vasta comprensione visiva del mondo” stando alle dichiarazioni di Meta. In pratica, Llama 4 può sia comprendere descrizioni testuali sia analizzare contenuti visivi all’interno di un’unica rete neurale unificata.

Questa è un’evoluzione rispetto a modelli multimodali precedenti (inclusi alcuni Llama 3 sperimentali) che combinavano separatamente un modello linguistico e uno visivo: Llama 4 integra invece fin dall’inizio le capacità di visione nel modello di linguaggio. Per l’utente finale ciò significa poter costruire applicazioni in cui un singolo modello può, ad esempio, leggere un’immagine (es. il grafico di un report) e generare testo (es. un’analisi del grafico), senza dover concatenare più sistemi diversi.
Al momento, Meta ha attivato le funzioni multimodali solo in forma limitata (negli Stati Uniti e in lingua inglese) attraverso il proprio assistant Meta AI integrato in WhatsApp, Messenger e Instagram. Ma gli sviluppatori di terze parti possono già sfruttare Llama 4 Scout e Maverick per generare sia testo che immagini o codice, aprendo la strada a nuove categorie di applicazioni AI personalizzate.
Benchmark, prestazioni, accuse
Fin dal momento dell’annuncio, Meta ha pubblicato numeri impressionanti sulle prestazioni di Llama 4 nei test interni. In base ai benchmark condotti in casa, Llama 4 Maverick supererebbe modelli del calibro di GPT-4 (versione ottimizzata per open source, denominata GPT-4o) di OpenAI e Gemini 2.0 di Google su una serie di compiti, tra cui programmazione, ragionamento logico, comprensione di lingue diverse e perfino riconoscimento di immagini.
Allo stesso tempo, Meta ammette che Maverick non raggiunge ancora i risultati dei modelli di ultimissima generazione come Gemini 2.5 Pro di Google, Claude 3.7 “Sonnet” di Anthropic o GPT-4.5 di OpenAi.
In altre parole, Llama 4 si posiziona appena sotto lo stato dell’arte assoluto, ma con la promessa di un miglior rapporto costi-prestazioni. Behemoth, il futuro modello più grande, avrebbe performance persino superiori.
Meta per ora non ha pubblicato un technical report esaustivo di Llama 4, limitandosi a diffondere risultati selezionati e affermazioni attraverso comunicati e post sul blog.
Le verifiche indipendenti iniziali su Llama 4 hanno dipinto un quadro più sfumato. La comunità AI ha accolto con entusiasmo la disponibilità open source dei modelli, ma ha riscontrato prestazioni eterogenee a seconda dei compiti e delle versioni utilizzate. In particolare, alcuni esperti hanno evidenziato che i punteggi di Llama 4 nei benchmark pubblici non “stracciano” nettamente quelli di modelli open source già esistenti di dimensioni comparabili (sotto 70 miliardi di parametri).
E così sono subito comparse conversazioni in cui circola il sospetto che Meta abbia “truccato” i risultati inviando alle piattaforme di benchmark una versione modificata ad hoc del modello. In particolare, l’attenzione si è concentrata sulla Leaderboard di LM Arena, un sito indipendente dove i modelli vengono valutati in duelli automatici (arena).
Llama 4 Maverick compariva ai vertici di quella classifica con un Elo di 1417 punti – secondo solo a Gemini 2.5 Pro – ma alcuni ricercatori hanno notato comportamenti differenti tra il Maverick scaricabile pubblicamente e quello testato su LM Arena. È emerso infatti che Meta avrebbe sottoposto ai benchmark una versione sperimentale e non rilasciata di Maverick per ottenere punteggi migliori.

Questo “caso LM Arena” ha acceso la discussione: Meta sta giocando pulito nella presentazione dei suoi risultati? Alcuni hanno persino ipotizzato che i modelli potessero essere stati addestrati su parti dei set di test, violando le convenzioni etiche dei benchmark.
Meta ha reagito prontamente alle accuse. Ahmad Al-Dahle, vicepresidente per l’AI generativa, ha dichiarato pubblicamente che tali insinuazioni sono “semplicemente false” e che l’azienda “non addestrerebbe mai” i modelli Llama sui dati di valutazione. Ha spiegato che la discrepanza su LM Arena è dovuta all’uso di una variante di chat ottimizzata – definita come experimental chat version – impiegata per mostrare il potenziale di Maverick, ma che la versione stabile rilasciata può differire in alcuni comportamenti iniziali. Al-Dahle ha riconosciuto che gli utenti stavano osservando una qualità “mista” nelle prestazioni di Maverick e Scout a seconda dell’infrastruttura utilizzata, complici alcuni bug e differenze di configurazione nei vari cloud partner .
Meta, a suo dire, ha voluto rendere disponibili i modelli “non appena pronti”, accettando che ci sarebbero voluti alcuni giorni per mettere a punto tutti gli endpoint pubblici e allineare le versioni. L’azienda assicura che continuerà a lavorare con la comunità per affinare i modelli e correggere eventuali problemi emersi nei primi test.
Guardrailing, censura, politicamente corretto
Llama 4 è stato deliberatamente tarato per non sottrarsi a domande su temi politici e sociali controversi, dove i modelli precedenti spesso si rifiutavano di rispondere. Meta sostiene che il nuovo sistema fornisce risposte utili e fattuali “senza giudizi” e in modo più equilibrato rispetto al passato.
Questo può favorire un uso più libero dello strumento in contesti aziendali, dove si potrebbero voler discutere scenari ipotetici o questioni delicate senza troppi filtri. D’altra parte, rimane cruciale monitorare cosa effettivamente i modelli rispondano su questi temi: ridurre le censure potrebbe amplificare bias preesistenti o portare alla generazione di contenuti discutibili se le salvaguardie non sono adeguate.
La comunità scientifica sottolinea che eliminare completamente i bias è un problema tecnicamente complesso e ancora irrisolto. Proprio per questo alcuni esperti invitano alla cautela: sebbene modelli come Llama 4 rappresentino un passo avanti, è fondamentale valutare con rigore la qualità delle risposte (completezza, correttezza, imparzialità) soprattutto quando essi iniziano a essere impiegati in applicazioni reali dove un errore o un’informazione falsa possono avere conseguenze concrete.
Open source e Open Weights
Con Llama 4, Meta conferma la propria strategia di spingere verso modelli di AI open source o “open weights”, distinguendosi dai competitor che mantengono chiusi i pesi delle loro reti neurali. Ma cosa significa realmente “open” in questo contesto? In ambito software tradizionale, open source implica la possibilità di ispezionare, modificare e ridistribuire liberamente il codice.
Cosa sono i pesi?
I "pesi" dei modelli linguistici di grandi dimensioni (LLM) sono parametri numerici appresi durante l'addestramento su enormi quantità di dati testuali. Rappresentano la "conoscenza" del modello e determinano come elabora e genera il linguaggio. Durante l'addestramento, questi pesi vengono continuamente aggiustati. Una volta addestrato, i pesi rimangono fissi e vengono utilizzati per generare nuovo testo in risposta a un input.
Nel campo dei modelli di AI, l’apertura riguarda in primo luogo la disponibilità dei pesi addestrati: chiunque può scaricarli ed eseguirli localmente, adattarli (fine-tuning) e integrarli nelle proprie applicazioni. Meta, ad esempio, ha reso scaricabili i modelli Llama 4 Scout e Maverick per sviluppatori e partner attraverso il sito llama.com e repository dedicati.
Come notato da un’analisi di Vox, un approccio open source limita il potere dei governi censori e favorisce la ricerca collaborativa, evitando che i progressi dipendano esclusivamente da interessi aziendali o governativi, o comunque di chi ha il controllo dello strumento. In altri termini, l’apertura può accelerare l’innovazione: comunità di ricercatori indipendenti possono individuare bug, migliorare l’architettura o trovare nuovi impieghi per i modelli a un ritmo che difficilmente un team chiuso potrebbe eguagliare.
Va però sottolineato che “open” non significa senza condizioni. Anche Llama 4, come il predecessore Llama 2, è rilasciato con una licenza d’uso specifica che impone alcuni paletti. In particolare, Meta esclude gli utilizzatori europei: qualsiasi utente o azienda che abbia sede legale nell’Unione Europea non è autorizzato a usare o distribuire i modelli Llama 4, stando ai termini di licenza. Chi è in Europa, tuttavia, può usare servizi terzi basati su Llama 4 - perché in questo caso eventuali responsabilità legali ricadono appunto sull’intermediario.
Meta, compreso il CEO Mark Zuckerber, ha spesso criticato le normative europee e si è unito al coro di voci secondo cui certe regole ostacolerebbero l’innovazione e impedirebbero alle aziende di crescere e svilupparsi, creando così ricchezza e posti di lavoro.
Più realisticamente, Meta non vuole incappare in sanzioni dovute a leggi come GDPR o AI Act.
Inoltre, la licenza di Llama 4 vieta l’uso a certe categorie di aziende (ad esempio competitor con oltre 700 milioni di utenti mensili, che devono richiedere un permesso speciale a Meta).
Dunque, sebbene si parli comunemente di Llama 4 come modello “open source”, in realtà sarebbe più corretto definirlo open-access con restrizioni: i pesi sono aperti, ma non al 100% per tutti gli attori. Ciò alimenta anche il dibattito su cosa debba rispettare un modello per essere considerato davvero open source – l’Open Source Initiative ad esempio sta lavorando a definizioni ad hoc che includano anche trasparenza sui dati di addestramento, non solo sul codice.
I pericoli di un’AI Open Source
L’altra faccia della medaglia sono i rischi legati all’apertura. Un modello open source, una volta rilasciato, può essere utilizzato da chiunque per scopi potenzialmente malevoli. Un rischio che riguarda qualunque strumento AI, ma dove si sono meno controlli aumentano le possibilità di abuso e misuso.
Rimuovere i filtri di sicurezza da Llama 4, ad esempio, è tecnicamente possibile e relativamente poco costoso, come dimostrato in passato con Llama 2. Ciò significa che attori con intenti nocivi potrebbero addestrare versioni di Llama 4 che generano disinformazione su larga scala, propaganda politica automatizzata o contenuti d’odio, sfruttando il fatto che le piattaforme di distribuzione (social, messaggistica) non sono ancora in grado di rilevare con certezza i testi generati da Ai.

Un documento dell’IEEE avverte che modelli “senza guinzaglio” possono avere conseguenze profonde sull’ecosistema informativo, ad esempio facilitando la creazione di deepfake non consensuali e campagne di scam personalizzate su vasta scala. Un altro timore è l’uso di AI aperte per automatizzare attività illecite: dalla creazione di malware su misura, alla progettazione di armi biologiche o chimiche, come ipotizzato in alcuni scenari di ricerca sui rischi emergenti.
Sono tutte cose che stanno già succedendo oggi, e il pericolo non può che aumentare con l’arrivo di uno strumento più potente come è appunto Llama 4.
Llama 4 per le aziende e per il lavoro
Dal punto di vista delle opportunità per le imprese, i modelli open source come Llama 4 offrono diversi vantaggi concreti. Primo fra tutti, la possibilità di personalizzazione: un’azienda può prendere Llama 4 e affinarlo sui propri dati (documentazione interna, basi di conoscenza proprietarie, conversazioni di supporto clienti, ecc.) per ottenere un assistente virtuale o un sistema AI su misura. Questo consente di avere modelli altamente specializzati nel proprio dominio, con un tono e uno stile controllato, senza dover condividere informazioni sensibili con fornitori esterni.
Proprio la sovranità sui dati e la sicurezza rappresentano un beneficio chiave: disponendo dei pesi localmente, le organizzazioni possono far girare l’AI nei propri server o cloud privati, mantenendo il pieno controllo sulle informazioni trattate.
La spesa per dotarsi della potenza necessaria sarebbe enorme, ma forse accettabile in scenari specifici. Sopratutto dove è un obbligo legale trattare i dati in un certo modo.
Settori regolamentati (finanza, sanità, pubblica amministrazione) possono così sfruttare capacità avanzate di AI senza incorrere in problemi di conformità legislativa, cosa che invece spesso frena l’adozione di servizi cloud di terze parti.
Dal lato dei costi, l’open source può aumentare il costo dell’hardware, ma se non altro si può risparmiare sulle licenze - sia quelle one time sia gli abbonamenti. Il costo di un valido consulente o di un MSP, tuttavia, non andrebbe mai sottovalutato.
Una volta chiarito il dilemma relativo ai costi e all’efficienza, l’arrivo di modelli avanzati come Llama 4 apre nuove possibilità di innovazione e automazione nel mondo aziendale.
Organizzazioni di ogni settore possono sfruttare questi sistemi per rendere più efficienti processi esistenti e crearne di nuovi. Ad esempio, in ambito marketing e comunicazione, Llama 4 può automatizzare la generazione di contenuti testuali di qualità: post social, descrizioni di prodotti, bozze di comunicati stampa o newsletter, il tutto adattato al tone of voice del brand tramite opportune personalizzazioni.
Nel servizio clienti, si possono creare chatbot e assistenti virtuali più intelligenti e contestualizzati, capaci di attingere a basi di conoscenza aziendali per fornire risposte accurate e personalizzate ai clienti, 24 ore su 24. Sul fronte dell’analisi dei dati e degli insight di business, la capacità di Llama 4 di digerire enormi quantità di testo significa poter interrogare in linguaggio naturale archivi documentali, rapporti o research papers ottenendo sintesi e risposte specifiche. Immaginiamo un’azienda di consulenza che alimenta il modello con migliaia di pagine di report interni: Llama 4 Scout potrebbe riassumere le principali raccomandazioni o estrarre correlazioni, offrendo agli analisti spunti più rapidamente di una lettura manuale.
Analogamente, la possibilità di fornire codice sorgente come input apre scenari per l’IT: Scout e Maverick potrebbero esaminare vasti codebase aziendali per documentare funzioni, trovare bug noti o suggerire refactoring, attività che oggi richiedono molte ore di lavoro umano.
Grazie alla natura open di Llama 4, molte di queste applicazioni possono essere sviluppate in-house dalle aziende, mantenendo il controllo sull’IP e sui dati. Una società potrebbe raffinare un modello Llama 4 per diventare un “esperto” del proprio dominio – ad esempio un’assistente legale addestrato su tutta la giurisprudenza e i contratti aziendali, oppure un modello in ambito biomedicale allenato su pubblicazioni e cartelle cliniche (nel rispetto delle normative).
Questo livello di personalizzazione, combinato con l’assenza di vincoli di licenza onerosi, incentiva la sperimentazione rapida: team interni possono prototipare soluzioni AI ad hoc senza attendere approvazioni o budget per servizi esterni, abbassando la barriera all’adozione.
Llama 4 come copilota
Llama 4, per le sue caratteristiche, è un candidato ideale per sviluppare copilot in molteplici domini. In campo programmazione software, ad esempio, un’azienda può implementare un copilota simile a GitHub Copilot ma alimentato da Llama 4 e magari addestrato sul proprio repository di codice: gli sviluppatori riceverebbero suggerimenti di completamento e spiegazioni di funzioni in linea con gli standard e le librerie interne.

Nel settore finanziario, si potrebbe avere un copilota per gli analisti che genera riassunti di notizie di mercato, propone bozze di report finanziari basati su dati aggiornati o effettua analisi di scenario su bilanci, liberando tempo ai banker per la valutazione strategica. Anche nelle attività di project management e lavoro d’ufficio, i copiloti AI stanno diventando realtà: Microsoft, ad esempio, sta integrando funzioni di questo tipo in Office 365 con il suo Copilot (basato su GPT-4).
Un’azienda potrebbe preferire una soluzione su misura con Llama 4 per motivi di privacy e compliance normative, ottenendo assistenti che preparano minute di riunioni, schedulano attività o filtrano le email, apprendendo dalle specificità organizzative. La diffusione di questi “colleghi digitali” promette di far evolvere molte professioni: non più solo strumenti passivi, ma partner attivi nei flussi di lavoro.
In generale, gli esperti concordano che l’AI tenderà più ad aumentare che a sostituire il lavoro umano nei prossimi anni. Si parla di previsioni a breve termine, mentre sul lungo periodo la riduzione del lavoro è una preoccupazione molto più seria.
Un recente report di IBM ha rilevato che l’87% dei dirigenti si aspetta che l’AI potenzi i lavori invece di rimpiazzarli. Ciò significa che molte professioni verranno ridisegnate: le mansioni ripetitive o standardizzate verranno automatizzate, mentre maggiore enfasi verrà posta sulle attività in cui l’essere umano eccelle – creatività, pensiero critico, relazione interpersonale, problem solving.
Ad esempio, un copywriter potrà delegare all’AI la stesura di una bozza di articolo o di uno slogan, ma rimarrà fondamentale nella rifinitura del messaggio e nell’ideazione strategica della campagna. Allo stesso modo, un commerciale potrebbe farsi preparare dall’AI un’analisi del profilo del cliente e una bozza di proposta, per poi dedicare più tempo alla trattativa e alla costruzione del rapporto personale.
È verosimile che assisteremo a una riqualificazione massiva: i lavoratori dovranno acquisire competenze digitali e data literacy per collaborare efficacemente con strumenti AI. Le aziende, da parte loro, dovranno investire in formazione continua affinché il personale possa “lavorare fianco a fianco con l’AI”. Chi saprà adattarsi e integrare queste nuove tecnologie vedrà aumentare la propria produttività e valore aggiunto. Al contrario, chi resterà ancorato ai vecchi metodi rischierà di venire obsolescente in mercati sempre più dinamici e guidati dai dati.
Naturalmente, l’impatto non sarà solo positivo o neutrale: alcuni ruoli scompariranno o si ridimensioneranno con l’automazione. Professioni basate quasi interamente su compiti ripetitivi e ben strutturati (per esempio, alcuni ruoli di back office, data entry, traduzione semplice) potrebbero essere rimpiazzate in buona parte da sistemi come Llama 4.
Considerazioni finali
L’annuncio di Meta Llama 4 si colloca in un momento di entusiasmo straordinario attorno all’AI generativa, ma anche di crescente scrutinio sulle sue effettive capacità e sui suoi effetti collaterali. Come spesso accade con le tecnologie emergenti, siamo di fronte a un mix di hype e realtà: da un lato aspettative altissime e una narrazione che presenta ogni nuovo modello come rivoluzionario; dall’altro, limiti tecnici concreti e sfide che richiedono tempo per essere risolte.
Llama 4 sembra incarnare questa dicotomia. È innegabile che rappresenti un passo avanti significativo – per architettura (MoE), per apertura, per contesto e multimodalità – ma non è una soluzione magica a tutti i problemi dell’AI. Le prime prove lo mostrano altamente promettente in certi ambiti, ma ancora perfettibile e in linea con l’evoluzione incrementale che il campo dell’AI ha sempre avuto.

Per aziende e imprenditori, il messaggio deve essere di cauto ottimismo: esplorare le opportunità offerte da Llama 4, ma con la consapevolezza dei suoi limiti attuali e della necessità di competenze solide per integrarlo efficacemente.
Un punto emerso chiaramente è la responsabilità condivisa nell’adozione di queste tecnologie. Meta, rilasciando Llama 4, ha il dovere di continuare a supportarlo, correggerne i bias, migliorarne la sicurezza e – auspicabilmente – renderlo disponibile anche in contesti regolamentati come l’Europa quando possibile. Ma anche le aziende utilizzatrici hanno un ruolo cruciale: quello di promuovere un’adozione consapevole. Ciò significa non utilizzare Llama 4 (o qualunque altro modello) come un oracolo infallibile, bensì stabilire processi di human-in-the-loop dove le risposte dell’AI vengano verificate, specialmente nelle decisioni critiche.
Significa anche valutare attentamente gli ambiti applicativi: laddove un errore dell’AI può causare danni seri (pensiamo al settore sanitario o legale), bisogna predisporre misure di mitigazione e backup. Le aziende dovrebbero inoltre dotarsi di linee guida etiche interne per l’uso dell’AI, in linea con i principi di fairness e trasparenza, e comunicarle chiaramente ai propri stakeholder. In questo senso, chi adotta modelli open source come Llama 4 potrebbe contribuire attivamente alla comunità segnalando problemi, condividendo best practice e magari partecipando allo sviluppo di strumenti di auditing indipendenti.
Infine, una riflessione importante riguarda la sostenibilità di questa corsa all’AI. Modelli come Llama 4 richiedono una quantità enorme di risorse sia per l’addestramento sia per l’utilizzo. C’è una questione di costi energetici da considerare, ma anche e soprattutto di impatto climatico.
Finora abbiamo generato tonnellate di CO2 solo per generare immagini divertenti, e anche in azienda ci si appresta a fare lo stesso. A volte sarà per questioni serissime, come sviluppare un piano di marketing o creare un nuovo software aziendale. Altre volte sarà per cose che si potrebbero fare anche con soluzioni a minore impatto ambientale.
L’auspicio è che la comunità tech e scientifica lavori parallelemente su due fronti: da un lato modelli e algoritmi più efficienti (ad esempio, proprio l’approccio MoE di Llama 4 nasce anche con l’idea di rendere più efficiente il calcolo), dall’altro una maggiore trasparenza da parte dei big player sui consumi energetici e sulle emissioni legate ai loro modelli, affinché si possano adottare misure di compensazione o ottimizzazione.
Meta e simili dovranno rendere pubblici questi dati e impegnarsi a mitigare l’impronta carbonica dei propri progetti di AI, se vogliono dimostrare un approccio responsabile e lungimirante.
Questo commento è stato nascosto automaticamente. Vuoi comunque leggerlo?