


A fine giugno Redis ha annunciato importanti miglioramenti per il suo Redis Query Engine allo scopo di accelerare i carichi di lavoro relativi all'esecuzione di query e alle ricerche, aumentando il throughput e diminuendo la latenza. Nel dettaglio, il throughput è aumentato di 16 volte rispetto alla versione precedente
Per dimostrare le capacità del nuovo Redis Query Engine la firma software ha eseguito una serie di benchmark confrontando l'engine con quelli dei principali provider di database vettoriali sul mercato.
Oltre al tempo di ingestion e di creazione dell'indice, il team di Redis ha preso in considerazione anche il throughput e la latenza: il primo indica la capacità di un sistema di processare un elevato numero di query o grandi dataset in un breve periodo di tempo, mentre il secondo misura quanto velocemente le ricerche di similarità ritornano i risultati.
Il benchmark, eseguito considerando 7 tra i database vettoriali più usati, ha evidenziato che il nuovo engine di Redis supera tutti gli altri per tutti e quattro i dataset presi in considerazione, ovvero deep-image-96-angular, gist-960-euclidean, glove-100-angular e dbpedia-openai-1M-angular.
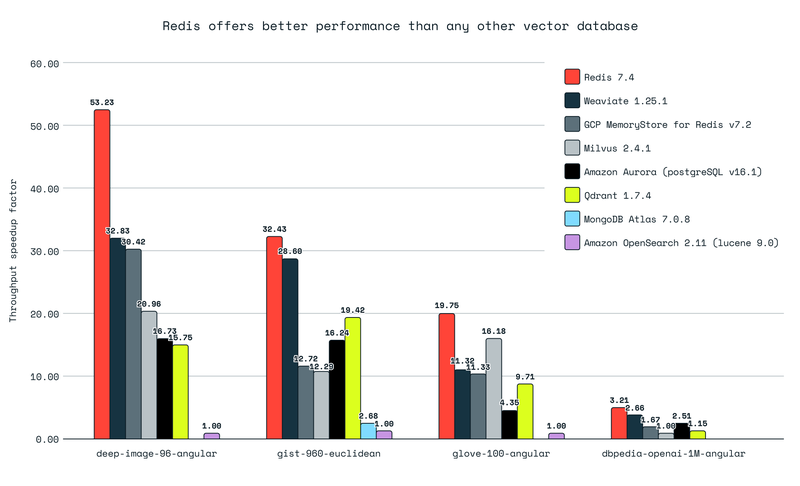
I ricercatori di Redis sottolineano che il nuovo engine è più veloce di altri database vettoriale puri, ovvero Qdrant, Milvus e Weviate: in numero di query per secondo, l'engine supera i tre rispettivamente di 3,4 volte, 3,3 volte e 1,7 volte. Redis Query Engine ha ottenuto ottimi risultati anche per la latenza, arrivando a essere fino a quattro volte più veloce di Qdrant e Milvus.
L'engine di Redis si è rivelato anche il più veloce nel processo di indexing e di creazione dell'indice. In alcuni casi, nei benchmark single client, le performance di Redis Query Engine e dei suoi competitori sono state allo stesso livello.
Relativamente ai database general-purpose, ovvero PostgreSQL, MongoDB e OpenSearch, l'engine di Redis ha ottenuto risultati ancora migliori, superando di 9,5 volte in termini di query per secondo PostegreSQL, di 11 volte MongoDB e di ben 53 volte OpenSearch.
Redis Query Engine ha ottenuto risultati migliori anche di database dei principali provider cloud (MemoryDB di Amazon e MemoryStore di Google Cloud), con dataset di ogni dimensione.
Il nuovo Redis Query Engine
I miglioramenti del Query Engine di Redis hanno coinvolto in primis l'architettura single-thread su cui si basa il motore: i ricercatori spiegano che l'engine si basa sul presupposto che la maggior parte dei comandi eseguiti sul database sia breve, con complessità temporale O(1), e che siano indipendenti l'uno dall'altro.
Basandosi su questa premessa, l'engine può suddividere i dati in shard indipendenti, garantendo un bilanciamento del carico e una distribuzione uniforme dei comandi tra le varie porzioni di database.
La ricerca, però, ha una complessità più elevata: le scansioni solitamente vengono eseguite in tempo logaritmico con complessità O(log(n)), con n che è il numero di punti del dataset mappati dall'indice. In questo caso combinare i risultati dei singoli predicati delle query e aggregarli è molto più pesante in termini di calcolo rispetto alle operazioni tipiche di GET, SET e HSET.

Aumentare il numero di shard non riduce la latenza in maniera significativa per operazioni complesse come la ricerca, anche se può distribuire il carico su più processi. Questo, spiegano i ricercatori, è un problema per l'architettura single-thread: la riduzione teorica della latenza non avviene a causa proprio della natura logaritmica degli indici, oltre per i costi aggiuntivi legati alla distribuzione e al post-processing.
Nel dettaglio, la ricerca vettoriale confronta il vettore richiesto con ciascuno dei "vettori candidati" proposti dall'indice, e la complessità del confronto è O(d), con d che è la dimensione del vettore. "In parole povere, ogni calcolo confronta i due vettori nella loro interezza. Si tratta di un'operazione pesante dal punto di vista computazionale" spiegano i ricercatori. Eseguendo questa operazione sul thread principale, questo processo viene "occupato" per un tempo molto maggiore rispetto ai carichi di lavoro normali.
Per scalare efficacemente si è reso necessario distribuire i carichi di lavoro orizzontalmente e il multi-threading verticalmente, abilitando l'accesso concorrente all'indexing.
La nuova architettura esegue più query contemporaneamente, ognuna su un thread separato. Redis ha introdotto il pattern producer-consumer per gestire l'esecuzione dei thread e quindi della pipeline di query in maniera concorrente.
Durante questa esecuzione, il thread principale continua a gestire le nuove richieste in entrata, per esempio comandi o nuove query, e i risultati delle query in arrivo dai thread.
I risultati condivisi dei benchmark dimostrano che la scelta di Redis è stata vincente. "I miglioramenti delle prestazioni sono stati coerenti, dimostrando che per ogni aumento di 2 volte del throughput delle query è stato necessario un aumento di 3 volte dei thread, indicando un utilizzo efficiente delle risorse in tutte le configurazioni".
I ricercatori sottolineano comunque che, in caso di query semplici, la scelta migliore rimane di eseguirle sul thread principale, senza attendere che si liberi un thread in background.
Il nuovo Query Engine di Redis è disponibile generalmente in Redis Software e sarà disponibile per Redis Cloud alla fine dell'anno.